

 Kelly Goolsby
Kelly Goolsby The ability to maintain an always-on environment is a necessity for ensuring business continuity and minimizing costly interruptions. Achieving high availability is critical to a robust IT strategy, forming the essence of efficient user experiences and reliable service delivery.
This article delves into the pivotal role of data center redundancy as a strategy to bolster high availability. You’ll learn how various redundancy models contribute to this goal and provide insights into balancing cost against reliability to achieve an optimal high-availability solution.
Understanding the importance of redundancy in data centers
Redundancy, in the context of data centers, is a fundamental strategy that involves duplicating components or functions within a system to enhance its reliability. It’s an insurance policy written in the language of hardware and protocols, designed to maintain operational functionality, even when parts of the infrastructure succumb to failure.
This approach to system design ensures that if one component fails, another can immediately take its place without interrupting service.
A data center resiliency survey reported that a staggering 80% of data center managers and operators have faced some form of outage in the last three years. These can lead to severe repercussions.
A good example of this is the 2007 incident at Los Angeles International Airport, where a glitch in a single desktop computer disrupted international flights for nine hours, underscoring the cascading effects of system failures.
Data center reliability is the silent guardian against data loss catastrophes, a buffer to downtime, and an efficiency catalyst for operations.
Beyond protecting data, redundancy serves the larger business context. It ensures uninterrupted business continuity, fosters customer trust and satisfaction by providing a seamless experience, and shields against the potential financial loss caused by operational downtimes.
While the upfront costs of implementing redundancy measures may seem daunting, it’s vital to reframe the perspective: investing in redundancy is not merely an expense but a safeguard. It’s a proactive measure to avert the potentially crippling consequences of system failures, which can cost far more in the long run than the initial investment in redundant systems.
Key components requiring redundancy
- Servers handle the processing of all tasks. Server redundancy is essential for any business as it allows a smooth transition to backup servers without service interruption in the event of a failure.
- Redundant storage systems ensure no single point of failure within the data storage infrastructure, safeguarding against data loss and allowing for quick data recovery and continuity.
- Redundant cooling systems are a necessity and a fail-safe, given the heat generated by high-powered computing. Systems like the upflow and downflow Computer Room Air Conditioning (CRAC) units in Liquid Web’s data centers prevent overheating and ensure optimal performance.
- Network redundancy minimizes the risk of connectivity loss due to a single point of network failure. Liquid Web exemplifies this with its geographically dispersed data centers featuring redundant network connections.
- Redundant power supplies, like the multiple UPS and redundant battery cabinets at Liquid Web, ensure that even in the face of power disruptions, the data center can continue to operate smoothly.
By weaving a net of redundancy across servers, storage, power, cooling, and network systems, data centers like those operated by Liquid Web are ideal for high availability. This multi-layered approach to redundancy adds a layer of protection while ensuring continuous service and maximum uptime.
The role of redundancy in enhancing high availability
High availability refers to a system’s ability to remain operational and accessible, minimizing the potential for downtime that can disrupt business operations. It is a binding metric for any data center’s performance, reflecting its reliability and efficiency.
The symbiosis between redundancy and high availability is one of mutual reinforcement. Redundancy acts as the fail-safe, where if one component fails, another immediately takes over to mitigate risks and enhance fault tolerance.
Consider a scenario where a single network link fails. In a system with network redundancy, the data flow is rerouted instantaneously through alternate pathways, maintaining connectivity.
Without redundancy, this single point of failure could lead to significant downtime, disrupting services and potentially leading to financial and reputational damage.
Liquid Web’s hosting solutions embody the principle of high availability. The company’s infrastructure is designed to minimize downtime through a robust, redundant environment that ensures operational continuity even when individual components fail.
Examining different models of redundancy: N+1, 2N, and 2N+1
Redundancy models in data center design dictate the reliability and robustness of the infrastructure. Understanding the technicalities of these models is crucial in tailoring a data center’s design to the operational requirements and risk tolerance of a business.
N+1 redundancy
The N+1 model provides a straightforward approach to redundancy. “N” represents the number of components necessary to run the system under normal operating conditions. The “+1” indicates the presence of one additional backup component.
For instance, if a data center requires five servers to handle its operational load, it would have six in an N+1 configuration: the original five plus one extra.
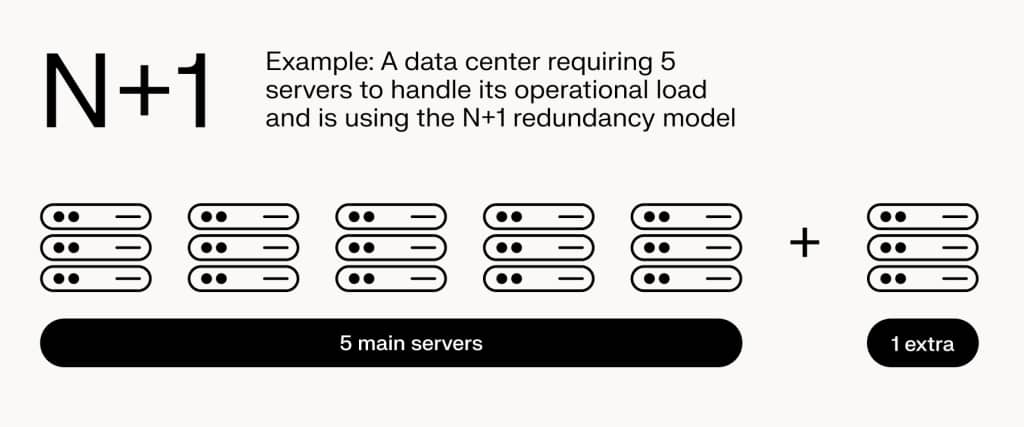
This model is designed to handle single-component failures with minimal impact on performance. It is scalable and relatively simple to maintain, making it suitable for growing data center operations.
However, it may require more frequent maintenance checks to ensure the backup component’s readiness due to the single layer of redundancy.
2N redundancy
Doubling down on reliability, the 2N model involves having a complete replica of the critical system, providing two sets of components for each one needed.
This means if the operational requirement is five servers, a 2N system would have ten.
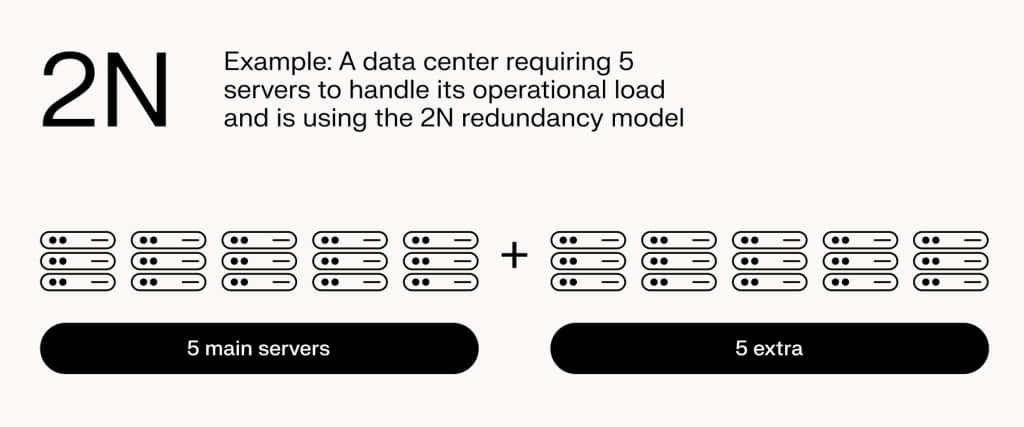
The redundancy this model offers is considerably high, ensuring that even multiple simultaneous failures can be handled, making it ideal for mission-critical operations where downtime is not an option.
This level of reliability comes at a higher cost, both financially and in terms of space and infrastructure needed to house the additional components. The 2N model necessitates rigorous real-time synchronization, typically through advanced storage area networks or clustering techniques, ensuring continuous data integrity and availability.
2N+1 redundancy
The 2N+1 model takes the 2N concept one step further by adding an extra layer of protection.
Following the previous example, a data center would have not just ten servers (2N) but eleven (2N+1).
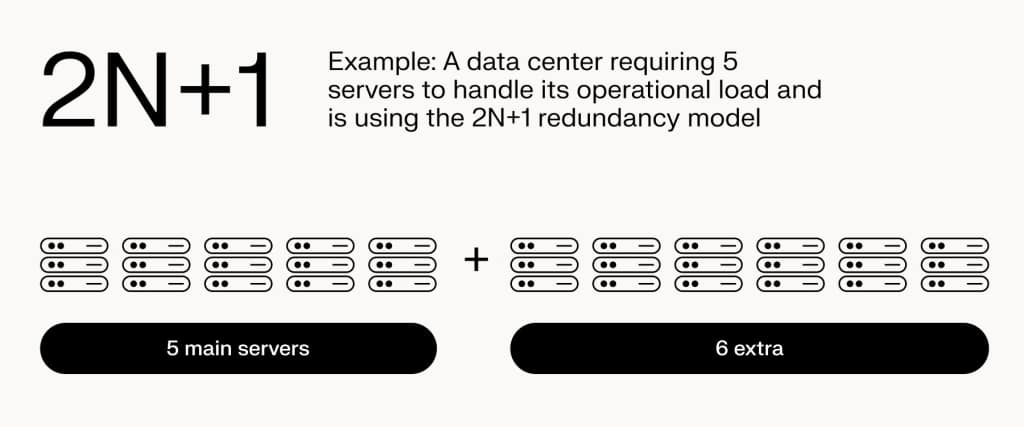
This additional component offers even greater fault tolerance and reliability, making it suitable for systems where downtime is extremely costly or dangerous. It often forms part of a comprehensive disaster recovery strategy, directly positively impacting the following:
- Recovery Point Objective (RPO), which is the maximum amount of data loss tolerable when the system goes through an unexpected disruption.
- Recovery Time Objective (RTO), which is the maximum time period for network recovery after an unexpected disruption.
Keep in mind that the 2N+1 model may demand complex maintenance and energy management strategies.
Here’s a comparative table to wrap the unique characteristics of each redundancy model at a glance:
| N+1 | 2N | 2N+1 |
|---|---|---|
| The most cost-effective option. | Provides a complete backup for every component, ensuring high availability. | Offers an additional safety net over the 2N model for unexpected failures or peak loads. |
| Provides sufficient redundancy for many operational scenarios. | Ensures operations continue even if an entire system fails. | Forms part of a comprehensive disaster recovery strategy. |
| Its reliability is lower, and it may not be suitable for environments where high availability is critical. | The trade-offs are higher costs and increased spatial and infrastructure requirements. | Most expensive in terms of initial investment, energy consumption, and spatial requirements. |
In real-world applications, Liquid Web’s European data center hub with 2N power redundancy provides an exemplary case study. It ensures that there is always a duplicate system ready to take over, thereby virtually eliminating power-related downtime.
Liquid Web’s Michigan data centers illustrate the N+1 approach with multiple Generac Diesel Generators and Liebert AC Units operating under the N+1 redundancy principle, ensuring at least one operational backup at all times.
This practical implementation demonstrates that while N+1 may have lower reliability than 2N or 2N+1, it still provides a significant safety net for critical operations.
How data center tiers relate to redundancy
Data center tiers are a standardized methodology used to define the uptime and performance of a data center. This classification system, which consists of Tier 1 through Tier 4, serves as a benchmark for comparing the infrastructure and capability of a data center, particularly in terms of redundancy and availability.
| Tier 1 | Has the most basic infrastructure features. There is no redundancy built in; thus, any planned or unplanned activity that takes a component offline can affect the data center’s overall operation. |
| Tier 2 | Includes partial redundancy for critical components, providing enhanced reliability over Tier 1 facilities. They might still experience disruptions during maintenance or unplanned outages. |
| Tier 3 | Offers N+1 fault tolerance, meaning there is at least one backup for every component. Capable of handling system or component failures with redundant components instantly taking over without impacting operations. |
| Tier 4 (the highest tier) | Provides 2N+1 fault tolerance, guaranteeing the highest levels of redundancy and operational continuity. They are designed to be fully fault-tolerant with multiple redundancies for every component, ensuring no single failure will impact the data center’s operations. |
According to the Uptime Institute, each data center redundancy level incorporates progressively more comprehensive redundancy features that directly correspond to higher levels of uptime. For instance, Tier 3 data centers, with their N+1 fault tolerance, are expected to achieve 99.982% availability, while Tier 4 facilities should reach 99.995% availability.
Understanding these tiers is essential for strategic planning. Businesses must align their infrastructure and redundancy strategies with the appropriate tier classification to meet their specific availability and performance requirements.
Liquid Web owns and operates its core data centers, emphasizing N+1 redundancy in power and cooling to ensure reliability and uptime. Here are the main highlights of Liquid Web’s data centers:
- The EU-Central data center is noted for minimal latency and maximum redundancy with connections to major Internet exchanges.
- The data centers in Lansing, Phoenix, and Amsterdam boast compliance with various industry standards and certifications and are equipped with fault-tolerant power systems, precision cooling, and robust security measures.
- All the data centers prioritize high-quality bandwidth and connectivity, highlighting a network’s reach to over 8,500 networks globally.
It’s clear that Liquid Web’s infrastructure is designed with full redundancy in mind to provide a high-quality hosting experience.
Cost and risk considerations in data center redundancy
Implementing redundancy in data centers involves weighing the costs against potential risks. Redundancy measures require significant investment in additional hardware, software, and ongoing maintenance.
However, a cost-benefit analysis often reveals that these expenses are far outweighed by the potential financial losses that could result from catastrophic system failures, which can be mitigated through redundancy.
The advent of virtualization and cloud-based solutions, like those offered by Liquid Web, have democratized access to cost-effective redundancy. For example, Liquid Web’s private cloud hosting utilizes fully redundant, enterprise-grade hardware with automatic failover capabilities, making high uptime levels more affordable.
Neglecting redundancy poses considerable risks, impacting service quality, customer satisfaction, and data integrity, which can lead to severe reputational and financial harm. Businesses must assess these factors to determine their optimal investment in redundancy infrastructure.
Choosing the right partner for maximizing uptime
In the quest for high availability, partnering with a reliable service provider is paramount. Liquid Web stands out among the crowd, offering robust support, data center infrastructure, and services with a 99.9% uptime guarantee.
Liquid Web’s service portfolio brings commercial advantages, such as:
- Minimizing losses due to downtime and enhancing business reputation through a consistent online presence.
- Having an always-on infrastructure via high availability hosting that encompasses server clusters, redundant power and cooling systems, and backup mechanisms.
- Maintaining continuous service, even during server disruptions, with features like automatic failover and load-balanced servers.
Additional benefits of Liquid Web include round-the-clock customer support, top-tier security, a professional services team, and assistance with migration.
Implementing an optimal redundancy strategy with Liquid Web
As you’ve explored throughout this article, data center redundancy is important to ensure high availability and fault tolerance.
Liquid Web serves as an ideal partner in your pursuit of a smooth, reliable, and redundant hosting solution. With a consultative methodology, premium services, and resilient infrastructure, Liquid Web is considered the preferred choice for businesses striving for high availability.
Liquid Web’s managed hosting services will alleviate your concerns about redundant systems, providing a team of experts to take an in-depth look into your IT infrastructure. They’ll evaluate potential points of failure and design redundancy plans accordingly, offering you the freedom to focus on your core business operations and growth.
Are you ready to set your business on the path to enriching reliability with an optimal redundancy strategy? Contact Liquid Web’s dedicated team today to guarantee resilient site reliability and continuity for your business!