◦ Fast and secure
◦ 24/7 expertise
AI web scraping: Should your business block or embrace it?
AI web scraping is raising questions for companies about data access, ownership, and control – particularly when it comes to content published on their websites.
In Liquid Web’s new AI web scraping study, 43% of businesses said they believe AI-powered scraping benefits their competitors more than them. Yet, 20% reported a financial boost from AI-driven traffic and referrals.
To help businesses navigate these competing outcomes, this report combines original survey data from business owners and developers with a practical guide to detecting, blocking, and managing AI bots.
Together, the study and guide offer insight and direction for those deciding how to handle AI web scraping in an increasingly automated digital landscape.
Key findings
- 1 in 5 businesses report a financial boost from AI scraping, with those benefiting seeing an average revenue increase of 23% due to AI-driven traffic and referrals.
- 43% of businesses believe AI scraping benefits their competitors more than their own business, but 30% are unsure of its impact.
- Over 1 in 4 businesses (27%) report higher engagement through AI-powered chatbots and discovery tools, and 26% have seen more brand mentions in AI-generated content.
- More than 1 in 5 businesses (22%) have noticed an increase in direct traffic from AI-driven search results.
How businesses are responding to AI web scraping
In a survey of 506 business owners and web developers, many reported having clear policies for how their websites handle AI bot traffic.
As AI web scraping becomes more common, organizations are taking varied approaches to control how and when large language models (LLMs) can access their data.
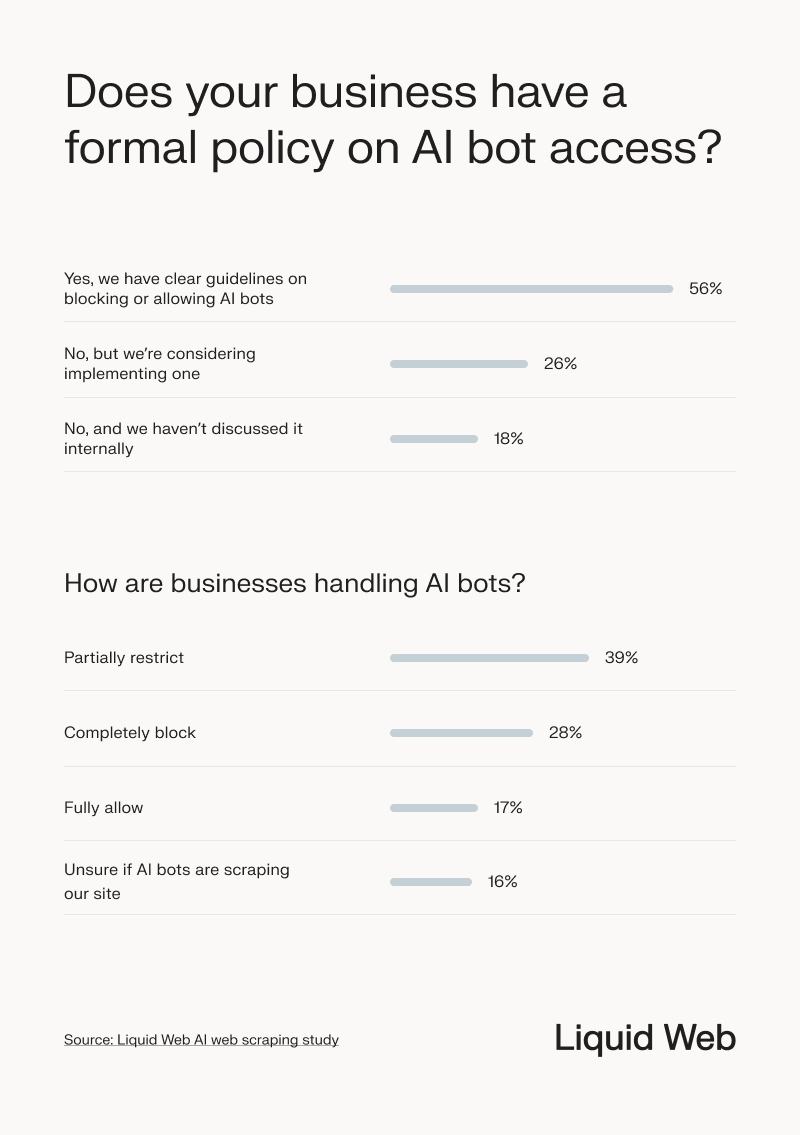
More than half of businesses (56%) reported having clear guidelines on whether to block or allow AI bots to scrape their websites for information. Much of this scraped data is used to train and power large language models like GPT, which can surface content in generative search results.
The sectors with organizations that most often had a formal policy in place were hospitality, finance, and government.
Blocking AI bot access is currently more common than allowing it:
- 28% reported completely blocking AI from scraping their websites. This was most common in the healthcare, tech, and marketing industries.
- 17% said their organization fully allows AI web scraping. Legal services, government, and hospitality were the top industries permitting unrestricted access.
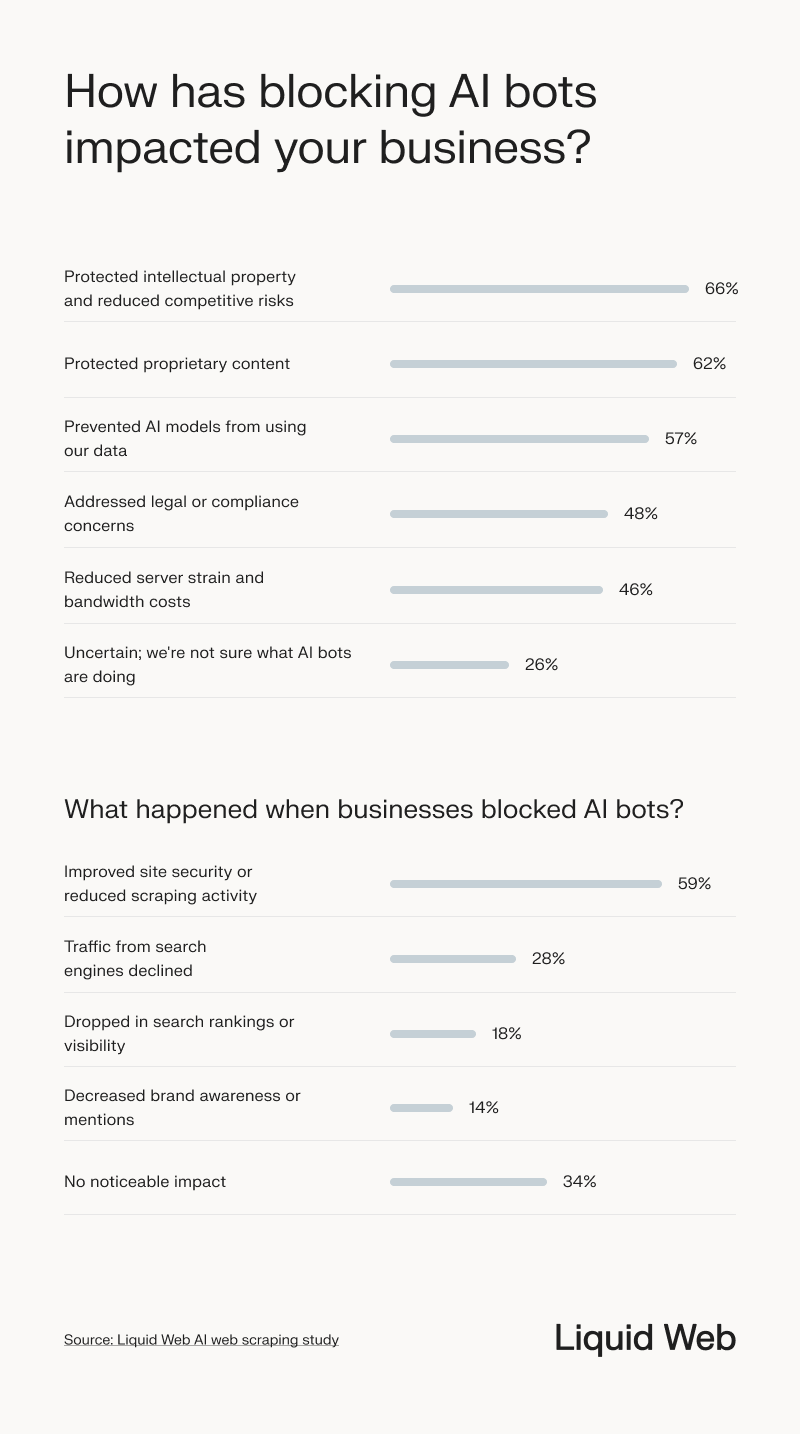
Blocking AI bots most often has helped businesses protect intellectual property and reduce competitive risks (66%), secure proprietary content (62%), and prevent AI models from using their data (57%). However, some companies face trade-offs.
While 59% reported improved site security, 28% saw a decline in search engine traffic, and 18% experienced a drop in rankings or visibility. More than a third (34%) said blocking AI bots had no noticeable impact on their business.
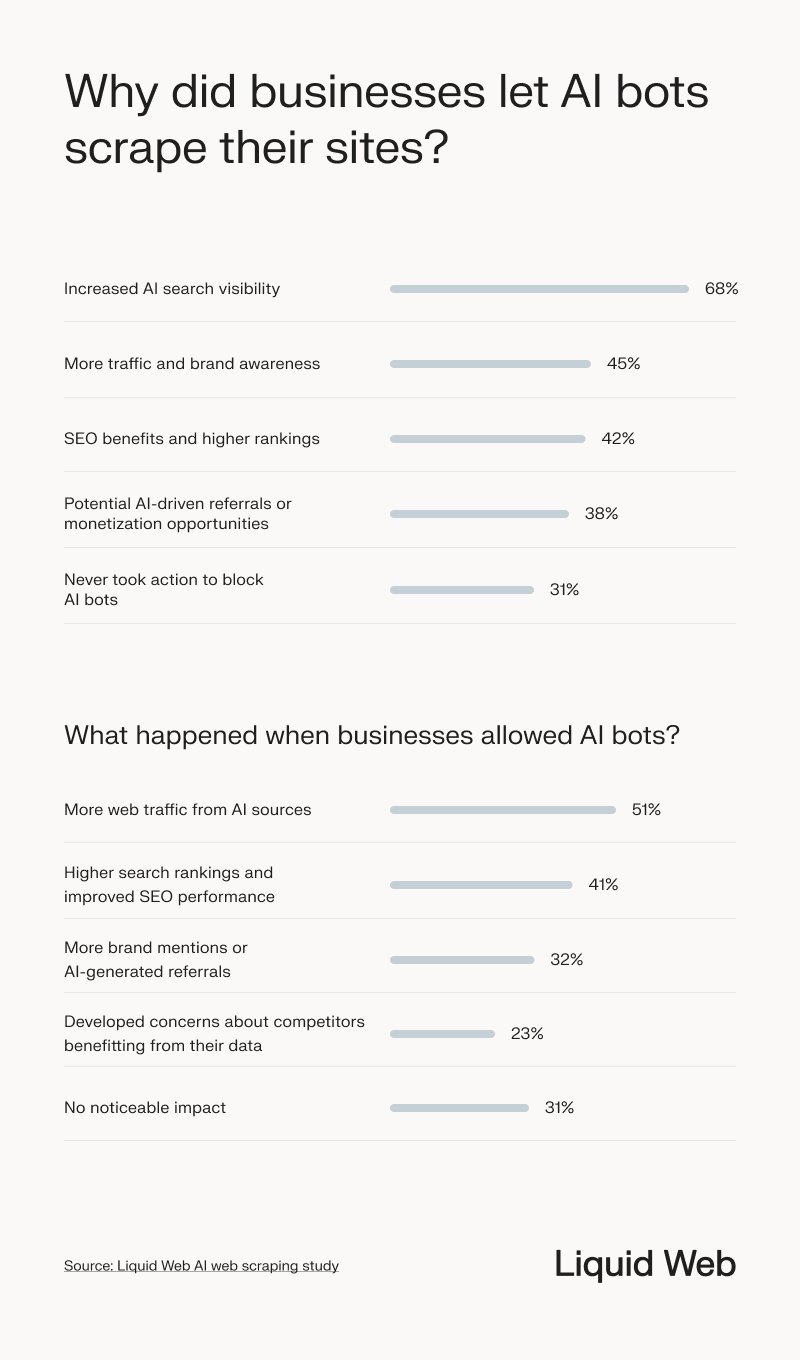
Businesses that allow AI bots to scrape their websites often do so for visibility and traffic benefits. The top reason cited was increased AI search visibility (68%), followed by more traffic and brand awareness (45%) and SEO improvements (42%).
When AI bots were allowed, 51% of businesses saw an increase in web traffic, and 41% reported higher search rankings. Almost a quarter (23%) said allowing AI web scraping caused concerns that competitors might benefit from their data, while 31% saw no noticeable impact from it.
While some businesses allow AI bots for the visibility and traffic benefits, others take a more selective approach – restricting certain bots while permitting others based on value, compliance, or server impact.
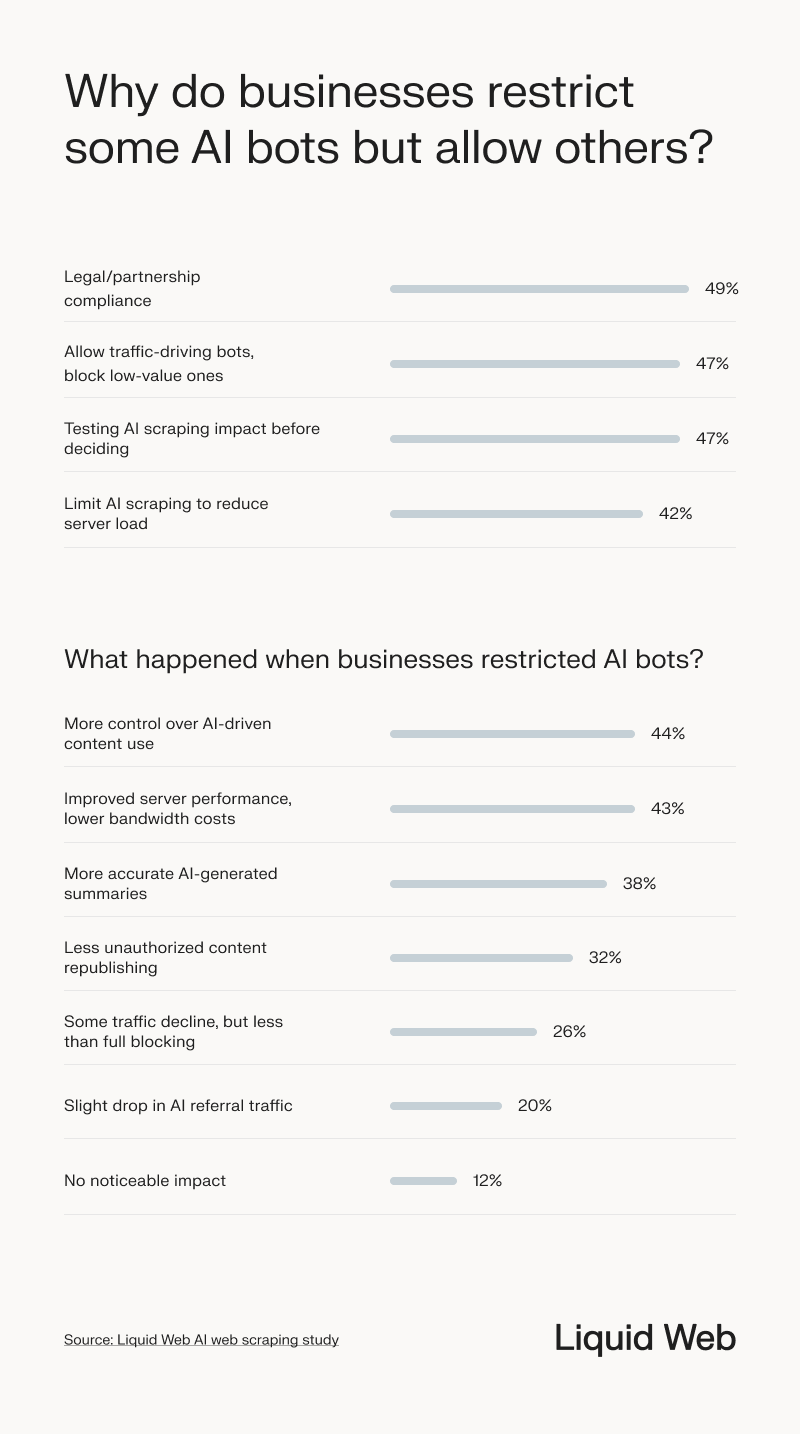
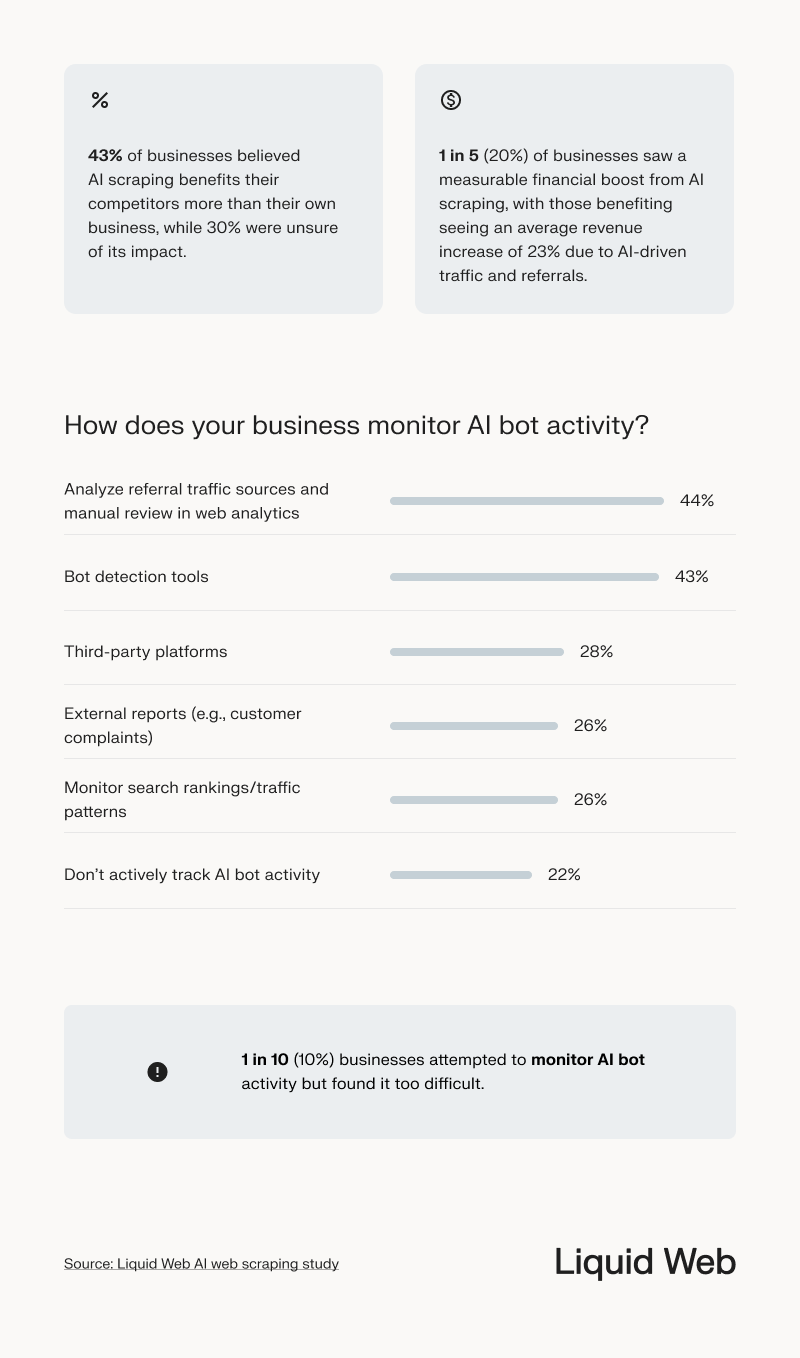
Among businesses that were unsure whether AI bots were scraping their sites, many cited internal roadblocks:
- More than half (56%) said the issue hasn’t been a priority.
- 1 in 3 didn’t know how AI bots might impact their site.
- 28% lacked the technical resources to monitor scraping activity.
- 26% were unsure whether blocking or allowing AI bots was the right course of action.
“AI is the new gateway to reach. Smart businesses are serving bots original content—on infrastructure built to scale, stay secure, and perform under pressure.”
Sachin Puri
President of Liquid Web

Does AI web scraping help or hurt businesses?
As AI-driven data collection becomes more widespread, businesses are split on whether it works to their advantage or puts them at risk.
Some have seen financial gains and increased visibility, while others worry that competitors benefit more from AI scraping than they do.
Many businesses see AI web scraping as more of a risk than an opportunity, with 43% believing it benefits their competitors more than their own company. This belief was most common in legal services, hospitality, manufacturing, finance, and tech industries.
Other companies have found ways to turn AI-driven traffic into a financial advantage:
- 20% reported a revenue boost from AI-generated referral traffic (visitors clicking through after seeing their content in AI-powered search results), with an average increase of 23%.
The biggest gains were seen in:
- Manufacturing (+28%)
- Finance (+28%)
- Healthcare (+27%)
- Tech (+22%)
- Marketing (+20%)
Beyond revenue, AI tools have helped businesses gain visibility. More than a quarter (27%) reported higher engagement through AI-driven chatbots and discovery tools, while 26% saw an increase in brand mentions within generative AI content. Another 22% noticed a rise in direct traffic from AI-powered search results.
Despite these benefits, not every company is willing to embrace AI scraping. Nearly 1 in 5 businesses (18%) have taken legal action, including sending cease-and-desist letters to prevent unauthorized data use.
“The key (especially for SMBs) is having smart infrastructure that enables intelligent and secure crawling, protects the user experience, and keeps costs predictable, so growth doesn’t come with surprises.”
Sachin Puri
President of Liquid Web
The AI web scraping dilemma: A guide for businesses
This guide breaks down how to identify and block an AI web scraper, protect high-value data, stay compliant with privacy laws, and make informed choices about AI bot access.
From detection techniques to advanced web scraping tools, it offers a practical framework for managing the evolving risks and rewards of AI web scraping.
1. How to detect AI bots scraping your site
AI-powered scrapers are becoming more sophisticated, making it harder to distinguish them from legitimate search engines.
Businesses need effective AI bot detection strategies to identify unauthorized data extraction and protect their digital assets.
Log analysis and traffic monitoring
Analyzing server logs is one of the most effective ways to detect AI bots. Suspicious activity often includes high-speed repeated requests, missing referrer headers, or unusual user-agent strings that don’t match known search engines.
Some well-known AI-powered scrapers include OpenAI’s GPTBot, Common Crawl, and other LLM-powered crawlers that scan web pages for data extraction. These logs can be exported to tools like Excel or Google Sheets for easier analysis and sharing across teams.
AI bot behavior tracking
Some AI bots try to mimic human behavior by adding randomized delays, simulating mouse movements, navigating pagination, or using rotating IP addresses to avoid detection. Other bots act like AI agents, adapting to user behavior in real time to bypass traditional detection methods.
Fingerprinting methods, such as JavaScript-based tracking, can help flag bot-like behavior by analyzing interaction patterns, browser characteristics, and device configurations.
AI-specific detection strategies
Large-scale AI training scrapers, especially those used by LLMs and machine learning models, often rely on automated tools to extract data across thousands of websites to build massive datasets. Many scrapers use open-source libraries that make it easy to crawl websites at scale.
Businesses can use CAPTCHAs, session tracking, and real-time IP behavior analysis to block or slow down these bots. Setting up rate limits and monitoring parsing activity in traffic logs can also help prevent scraping at scale.
2. Step-by-step guide to blocking AI scrapers
Preventing AI-driven web scraping requires a multi-layered approach. While robots.txt can block some bots, bad actors often ignore these rules.
More advanced methods help businesses prevent web scraping while allowing legitimate traffic. This section serves as a tutorial for beginners, offering steps to maintain control over digital content.
Implement robots.txt rules
A simple way to deter AI bots is to add robots.txt rules to disallow known scrapers. Many websites use templates to quickly generate these rules, making it easier to manage bot access without starting from scratch.
However, many AI scrapers ignore these guidelines, making additional protections necessary.
User-agent: GPTBot
Disallow: /
User-agent: CommonCrawl
Disallow: /The robots.txt file sits in the root of your website and gives instructions to web crawlers. The User-agent line specifies which bot the rule applies to, and Disallow: / tells that bot not to crawl any pages on the site.
Deploy CAPTCHAs and AI bot challenges
AI-adaptive CAPTCHAs adjust difficulty based on user behavior, making it harder for automated scrapers to pass.
CAPTCHAs can block bots while allowing human users to access content. Image-based, puzzle, and behavioral CAPTCHAs are effective, but AI is improving at bypassing simple tests.
Use anti-scraping tools and rate-limiting
Cloud-based anti-scraping tools detect and automate the blocking of bot traffic in real time. Some even offer no-code setup options to make it easier for non-technical teams to deploy protections.
Setting IP rate limits can throttle requests, reducing the impact of aggressive scrapers.
Employ JavaScript-based bot protection
Scrapers that rely on static HTML parsing (often built with tools like Python or Node.js) can be disrupted by dynamic rendering techniques. Honeypot traps, such as hidden form fields or fake links, can identify bots attempting to scrape websites and block them automatically.
Use API security and authentication
For businesses that offer data access via APIs, security is critical. Requiring API keys (api_key), JSON Web Tokens (JWT), or OAuth authentication helps ensure that only authorized users can access the data.
Setting scraper-resistant API endpoints, such as rate-limited or token-based access, can help prevent unauthorized data extraction.
3. The SEO impact of blocking AI bots
As AI-powered search engines like Google , Perplexity, and ChatGPT integrate web-scraped data into search results, businesses must consider how blocking AI scrapers affects their SEO performance and brand exposure.
While preventing LLMs from extracting web data can protect proprietary content, it may also reduce visibility in AI-generated search summaries and referral traffic.
Blocking AI scrapers too aggressively can lead to fewer brand mentions and less referral traffic from AI-driven search engines. Some businesses have seen a decline in indirect traffic after restricting AI access, as their content no longer appears in machine-learning-generated summaries.
However, when AI includes a website in its training data, it can drive new visitors through AI-powered recommendations and search results.
Businesses looking to protect their site without hurting SEO can take a balanced approach. Allowing Googlebot and Bingbot ensures visibility in traditional search rankings while blocking unauthorized AI scrapers prevents unrestricted data extraction.
Using structured data helps control what AI models can read, ensuring key content remains indexable while sensitive information stays protected.
4. Industry-specific web scraping protection strategies
Different industries face unique challenges when it comes to AI-powered web scraping. While some businesses worry about real-time data extraction, others struggle with pricing intelligence scraping or unauthorized content summarization.
Implementing industry-specific protection strategies helps businesses safeguard sensitive information while maintaining accessibility for legitimate users.
Finance and investment firms
Financial data is a prime target for AI-driven trading algorithms. Web scrapers can extract real-time pricing, market trends, and investment insights, potentially giving competitors an unfair advantage.
To prevent this, firms should restrict API access, enforce authentication for financial data, and limit requests from proxies that mask bot activity.
News and media outlets
AI-generated news summarization is reducing direct traffic to publishers, as users consume content without visiting the original source. Media companies can protect their content by implementing paywalls, limiting RSS feed access, and adding legal disclaimers that restrict AI models from repurposing their work.
Ecommerce and retail
Competitors often use AI scrapers to extract pricing and inventory data, allowing them to undercut businesses. To counteract this, ecommerce sites can hide pricing data for non-logged-in users, implement dynamic pricing models, and monitor for unusual spikes in real-time data requests.
SaaS and tech startups
Web scrapers frequently target freemium SaaS platforms to extract product insights and competitive data. To prevent unauthorized access, businesses should monitor for anomalous login behaviors, enable dynamic CAPTCHAs, and restrict access to high-value features behind authentication walls.
5. Legal and ethical considerations in web scraping
As AI-powered web scraping becomes more widespread, businesses must navigate legal risks, data ownership concerns, and ethical challenges. While scraping publicly available data is common, its legality depends on copyright laws, privacy regulations, and fair use policies.
Is AI web scraping legal?
The legality of web scraping varies by jurisdiction and context. Copyright laws often determine whether scraping violates fair use, especially when AI models repurpose content without permission.
A key legal precedent is LinkedIn vs. HiQ Labs, where the courts ruled that scraping publicly available data does not necessarily violate the Computer Fraud and Abuse Act (CFAA).
However, businesses still face legal risks when AI scraping conflicts with terms of service agreements.
How do GDPR, CCPA, and privacy laws impact web scraping?
The General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA) govern how personal data is collected and used, raising questions about privacy compliance in AI web scraping.
Businesses must ensure that scraping activities or attempts to block scrapers align with data protection laws, especially when handling user-generated content. Implementing privacy-focused policies and providing clear AI data usage disclosures can help businesses remain compliant.
What are the ethical considerations for blocking AI bots?
Some businesses are debating whether to publicly disclose their AI scraping policies. While blocking AI bots can protect data ownership, it may also limit the openness of AI-driven knowledge systems.
Companies must weigh data protection against ethical AI usage so that their policies balance security with accessibility.
Decision framework: Should you block AI scrapers?
There’s no one-size-fits-all answer when it comes to AI bot management. Whether you choose to block, restrict, or allow AI scrapers depends on your business goals, data sensitivity, and compliance requirements.
This decision framework helps guide a practical approach to web scraping protection and risk assessment.
Start by asking a few key questions:
- Is your data high-value, proprietary, or confidential?
- Would AI scraping harm or help your brand exposure?
- Do you have the resources to monitor and manage bot traffic effectively?
- Are you subject to legal or compliance standards for data handling (e.g., in healthcare, finance, or government)?
If the answer to most of these is yes, a more restrictive approach may be appropriate. Businesses with public-facing content that benefits from AI-driven visibility may choose to allow scrapers conditionally, using rate limiting, user-agent filtering, or structured data controls.
Regardless of your stance, it’s important to apply layered security measures. Integrating bot detection into existing security workflows can streamline response and reduce manual oversight. Regularly updating detection methods helps keep protection aligned with the latest scraping techniques.
With the right balance of access and control, businesses can protect their data while making informed decisions about their presence in the AI web scraping ecosystem.
Pros and cons of blocking vs. allowing AI scrapers
Blocking AI scrapers
Pros:
- Protects proprietary data and content from being reused without consent
- Reduces the risk of brand misrepresentation in AI-generated summaries or responses
- Helps meet compliance standards in industries with strict data protection requirements
Cons:
- May reduce visibility in AI-driven discovery tools or AI search results
- Requires ongoing monitoring and updates to stay effective
Allowing AI scrapers
Pros:
- Increases exposure through AI-powered search engines and assistant platforms
- Drives new referral traffic from users interacting with AI-generated content
- Positions your brand as a source of structured, relevant data
Cons:
- Risks unintended use or distortion of your content
- Offers less control over how and where your information appears
“AI bots are bound to reshape the web. From customer behavior to decision to selection to success. This is a traffic and visibility problem but a big revenue opportunity powered by authentic and original content.”
Sachin Puri
President of Liquid Web
Fair use statement
This content is based on proprietary research conducted by Liquid Web and is shared here under fair use for educational and informational purposes. If you reference any part of this article, please provide proper attribution with a link as the original source.
Share this content
<a href="https://www.liquidweb.com/white-papers/ai-web-scraping-study/" target="_blank" rel="noopener noreferrer">Liquid Web AI web scraping study</a>
Learn more about this study
Need more bot control?
VPS gives you root access and advanced controls to block bots, protect content, and optimize performance.
