



How to Set Up Plesk Backups in Cloud Object Storage
By default, Plesk typically stores backups on the server. This can, however, present a risk if the hard drive or RAID fails on the server. If this ever occurs, you can possibly lose both data and your backups. To avoid this situation, Liquid Web recommends storing additional backups in a remote storage location.
Plesk can configure multiple types of remote storage options including:
- Remote FTP Storage
- Amazon S3 Backup storage
- Liquid Web S3-compatible Object Storagewe
- Google Drive Backup Storage
- Microsoft OneDrive Backup storage
As a side note, we must state that storing scheduled backups in a remote cloud storage location is a premium feature and as such may increase licensing costs.
Plesk Backup Options
You can use more than one type of Plesk’s remote storage options, however, it can only utilize one S3 type of storage device at a time. For example, you can configure a remote FTP backup and a Liquid Web object storage device, and a Google Drive Backup, but you cannot use Amazon S3 Backup and a Liquid Web object storage device.
When creating backups, Plesk allows only one remote storage location at a time to be used. If you choose to store backups in more than one remote storage, you should create one backup for every remote storage you want to use. In this tutorial, we explain how to set up and configure a remote storage option for your backups in Plesk using the Liquid Web Object Storage option.
Liquid Web Object Storage
What is Object Storage?
LiquidWeb Object Storage is a service that can be used to store and access files via HTTP/HTTPS. Our Object Storage service is very similar to an Amazon S3 account. Your files are stored inside a resource that is known as a “bucket”. There can be multiple buckets for each account. Each bucket can contain multiple directories (folders), which can hold multiple files, such as .jpg .iso .mp3 .css .js .html etc.
The files on LiquidWeb's Object Storage are retrieved or placed in the buckets via http/https requests. The underlying technology that our cluster is built on a platform called Ceph, which is the same technology that is used for our Storm Block Storage product. In fact, both services utilize a similar cluster and hardware. Unlike the Storm Block Storage product, Object Storage does not allocate file systems, partitions, or block devices. Nothing is exported to a server to make it work. You interact with it entirely via http/https.
We do advise using a client like DragonDisk to connect to an S3 compatible storage device. DragonDisk allows a client to connect to an S3 type object storage medium.
Access Levels
You can configure each bucket to have various levels of access. Some buckets can be made “private” and can only be viewed by a certain user, with a certain key. Other buckets can be made “public” and the files located inside it can be read / downloaded by anyone on the Internet, or written too if write permissions are granted. Each customer account gets one Object Storage user when the product is purchased. The user can create multiple buckets in their account.
The Object Storage cluster replicates the files stored in buckets and provides a very high level of durability, files stored on our Object Storage cluster should never be lost as we have built in large amounts of redundancy to ensure data is safe.
Object Storage File Types
Customers can use our Object Storage to serve up parts of their website. Typically, this is used with images or other static content. The reason for doing this is to reduce the amount of traffic that interacts with your web server. This frees the server from doing extra work and allows it to focus more on handling PHP and MySQL calls. If someone wants to try to configure this, they must configure their website to work with the Liquid Web Object Storage. This is not always a simple task, but it can be done.
If someone would like to use Object Storage for serving up images, and you were to visit their blog post, our browser will first connect to the web server, get the HTML for the page, and then begin to render the page. If the website is configured to use Object Storage it should provide links to the images in our Object Storage, which the browser will then use to request the image. The URL for such an image could look something like — http://
Buckets
Files placed in object storage must be sent to a bucket. Buckets are used to define the Object Storage name-space for better organization. Once a bucket has been created and a file uploaded it can be accessed via https://
Common Use Cases
Clients can use Object Storage to store and serve up images and movies for a website (similar to how it works with a CDN). The difference between our Object Storage and a CDN is that we only have one location (Lansing), whereas a CDN will have thousands of locations to serve the images from, and will choose the closest location to the end user. Amazon and OVHcloud are two examples of what this looks like and how to do this can be done.
Terminology
- User — The object store user is automatically created when the “Create Object Store” button in manage is clicked. For now, there is one user per liquid web account: It is the unique ID of the object store sub-account. It cannot be changed or set manually, and is not needed to use the Object Store.
- Credentials: access_key_id — This is one half of an access key pair, essentially the “username” needed to access the account, and may be viewed on the object-store dashboard in manage/storm. Don't mistake the access keys for users! They are all the same user, just with different credentials. This is so that keys may be revoked selectively.
- Credentials: secret_access_key — The other half of the key pair, essentially the “password” needed to access the account, and may be viewed on the object-store dashboard in manage/storm.
- Endpoint — This is the url that the object storage cluster responds to requests. For our object store, this will always be `objects.liquidweb.services`
- Bucket — A bucket is an arbitrarily named logical unit of storage. Keys reference objects located inside of buckets. All objects exist at the same level inside the bucket.
- Key — The key is how you reference an object in a bucket. Essentially, this is the “path to file”.
- Object — An object is the data associated with a key. Objects can also have version id's, metadata, ACL info, and others.
Object Storage Design
If you take a look at the link below, you can see what the general design looks like https://
- myfirstbucket — The name of the bucket that I'm using to store the image. A bucket is basically a subdomain that gets added to the main endpoint. I could name a bucket thisismynewbucket and the URL would then be thisismynewbucket
.objects . liquidweb. services/ backups/ v12_25_20backup.tar.g. - objects.liquidweb.services — The endpoint that everyone will use to talk to our Object Storage cluster.
- /backups/ — This a folder or directory that is underneath the bucket at the beginning of the URL. You can have many folders under each bucket and the folder names do not need to be unique.
- 12_25_20backup.tar.gz — The last part is the actual file name located under the folder.
More Information on Buckets
You are not able to create a bucket inside a bucket. All buckets exist in one flat layer within the object store. Please keep in mind that buckets are incorporated into a domain name. As such, it is recommended that all bucket names be in compliance with DNS naming schema. Buckets with leading or trailing periods (“.bucket” or “bucket.”) are not good practice. Imagine the last two in a domain name (“.bucket”.objects.liquidweb.services or bucket.”.objects.liquidweb.services), clearly you'll run into problems. You can use periods within the bucket name as a sort of spacer (think sub-domains).
Consider the bucket “weekly.backups”, this will work just fine and could help with organization. The bucket
More Information on Prefixes
While it may appear that the object storage has a directory hierarchy, this is essentially a lie. Each file within a bucket is stored at the same level. The prefixing of the files help in preserving path information that is useful when restoring the files. When performing a GET request for the contents of a bucket you can use a delimiter to ensure that you are pulling the correct files. This is helpful when using the object storage as a versioning tool for a sites resources. Amazon outlines more info about limiting GET requests as well.
S3 Compatible Storage
Many services offer remote storage use APIs that are compatible with Amazon S3. Users can attempt to configure a S3-compatible storage option in Plesk, however there is no guarantee that it will work as expected. You can use the AWS CLI (AWS Command Line Interface) to verify an S3 compatible storage option for compatibility with Plesk. Also, the Cyberduck software can transfer client files that supports CDN and storage services like S3. If you can download or upload a file from the storage medium via the AWS CLI, you can probably use that storage with Plesk.
Configuring an S3 Compatible Storage Option in Plesk
To begin, the configuration, follow the next steps.
- First, Go to Tools & Settings > Tools & Resources > Backup Manager > Remote Storage Settings > Amazon S3 Backup
- If this is a new server, you can install the Amazon S3 Backup plugin by clicking on the Buy button in the Backup Manager window.

- Next, under the “Service provider”, dropdown menu option select “Custom” and then fill in the noted fields. Pay close attention to the “Bucket” and “Path” fields. These settings are noted in the Object Store Gateway in manage.
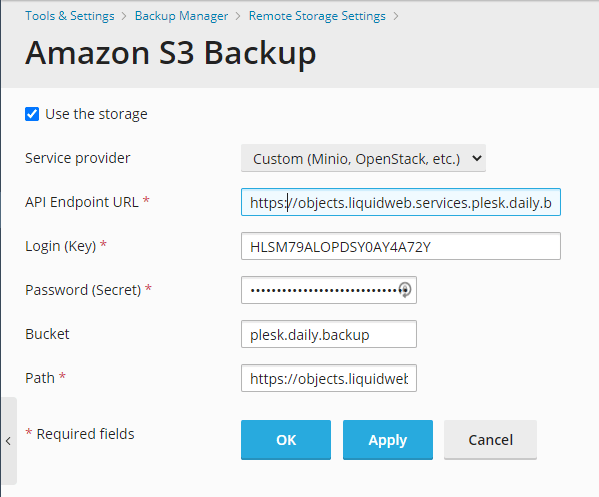
- You need to define the “Bucket name” and copy it into the “Bucket” field. In the “Path” field, you need to copy a path to the directory inside the bucket where you want to store backups.
- Lastly, click OK. The S3 compatible storage is now configured. You can select it when creating either a manual or a scheduled backup.
Like What You See?
Our Support Teams are filled with experienced Linux technicians and talented system administrators who have intimate knowledge of multiple web hosting technologies, especially those discussed in this article.
Should you have any questions regarding this information, contact us to answer any inquiries with issues related to this article, 24 hours a day, 7 days a week 365 days a year.
Related Articles:


About the Author: David Singer
I am a g33k, Linux blogger, developer, student, and former Tech Writer for Liquidweb.com. My passion for all things tech drives my hunt for all the coolz. I often need a vacation after I get back from vacation....




Our Sales and Support teams are available 24 hours by phone or e-mail to assist.
Latest Articles
How to use kill commands in Linux
Read ArticleChange cPanel password from WebHost Manager (WHM)
Read ArticleChange cPanel password from WebHost Manager (WHM)
Read ArticleChange cPanel password from WebHost Manager (WHM)
Read ArticleChange the root password in WebHost Manager (WHM)
Read Article